I’ve been ranting about Terraform a lot recently, and I’ve shown some pretty neat examples of building a VPC – however before now I haven’t got anything actually useful running.
In this post, we’re gonna change that, and launch ourselves a publicly available and scalable PAAS (Platform As A Service), built around Apache Mesos and Marathon with nginx and Amazon’s ELB for load balancing and Route53 for DNS.
Getting setup
You’ll need an AWS account, a Ubuntu machine and a domain you control (which doesn’t have to be in AWS) for this demo. My example domain is notanisp.net, and so the subdomain I’m going to use in all the examples is mesos.notanisp.net
You’ll also need the AWS cli and an ~/.aws/credentials file with a [demo] section in it.
In your AWS account, you need to go into the IAM menus, and create a ‘Role’, which will be given to the machines we launch, to allow them to find out other instances.
Your policy should be named describe-instances and the body of the policy should contain an inline policy:
{
"Version": "2012-10-17",
"Statement": [{
"Effect": "Allow",
"Action": "ec2:Describe*",
"Resource": "*"
}
]
}
If you’re feeling lazy, then you can just create the role with the policy of AmazonEC2ReadOnlyAccess.
Getting terraform
The easiest way to get my patched version of terraform is to build it in vagrant:
1 2 3 4 5 6 7 | |
Adding something like this:
[demo]
aws_access_key_id=AAAAAAAA
aws_secret_access_key=BBBBBBBBBBBBBBBBB
Or if you prefer (and you trust me!), here’s a .deb you should be able to just install:
Building your cluster
Once you’re all setup, you can get started building your cluster:
1 2 | |
This generates an ssh key (stored in id_rsa) to be able to ssh into your instances, and captures your IP (stored in admin_iprange.txt) to allow access to the Mesos and Marathon admin interfaces later. Note: You can edit the admin_iprange.txt file to allow more IPs access, but it is not recommended to change this to 0.0.0.0/0, as otherwise random people on the internet will be able to run jobs on your Mesos cluster!
Lets go ahead and build out the cluster:
1 2 3 4 | |
The last step will take a while, go grab a coffee.
Eventually, terraform will finish, with output like this:
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
Once it’s finished, go into the route 53 control panel, and you should see your subdomain zone. Go and grab its NS records:
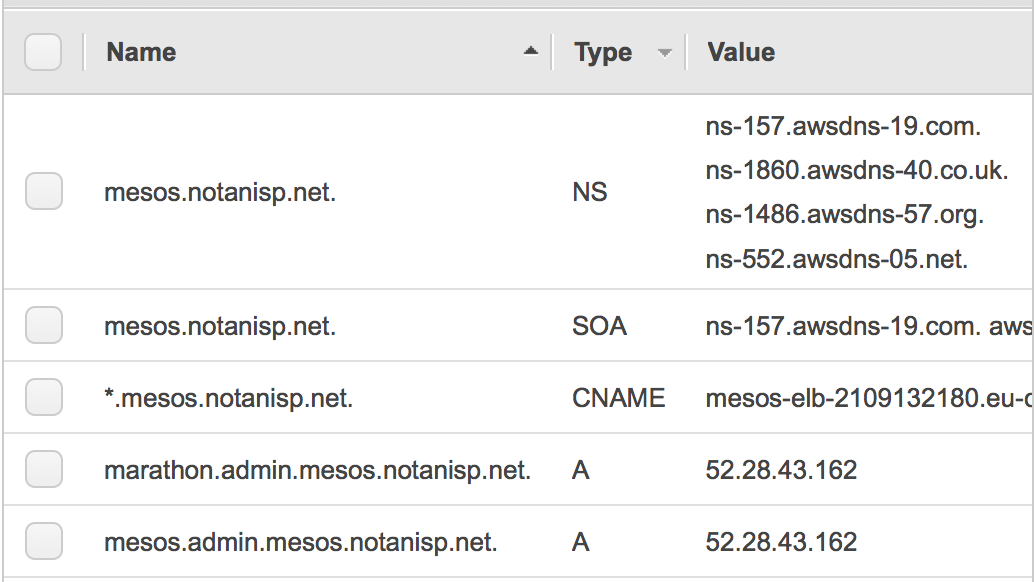
and put those into whatever you use to manage your main domain as a delegated record.
Gettins admin pages and launching an app
After DNS catches up, you should be able to resolve:
- mesos.admin.mesos.notanisp.net
- marathon.admin.mesos.notanisp.net
- www.mesos.notanisp.net
Hit http://marathon.admin.mesos.notanisp.net with your browser, and you should be able to see the Marathon admin screen. (And you can see the Mesos admin screen at http://mesos.admin.mesos.notanisp.net)
You can now launch an app!
I’ve automated the launching of an example application, so you can just say:
make deploywww
This will deploy the hello world app (from the mesosphere tutorial linked above) named ‘/www’ into marathon:
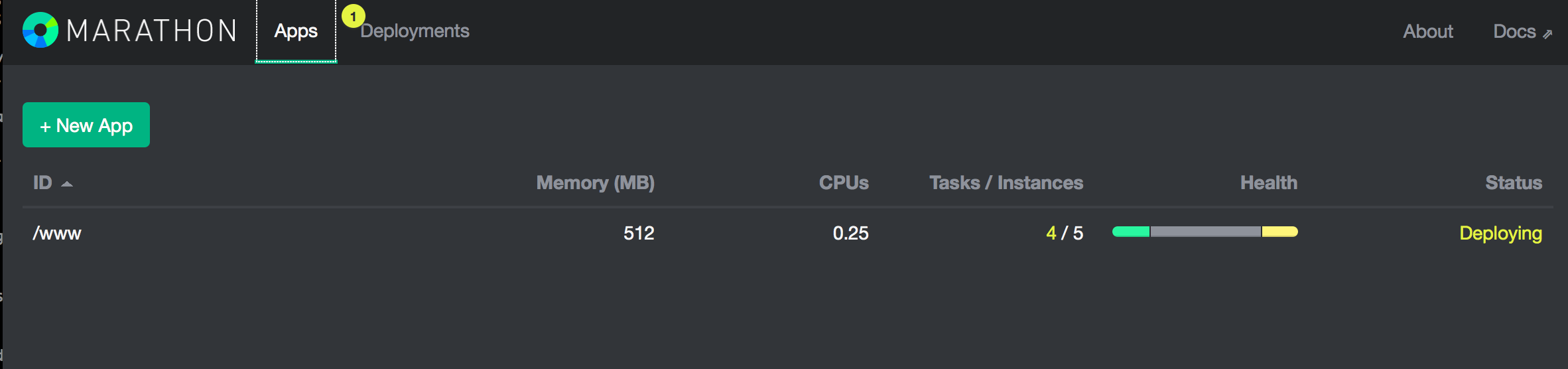
and after a couple of mins, you should be able to access it from http://www.mesos.notanisp.net
Any additional apps you launch in Marathon with names like /someapp will be automatically bound to a vhost on the load balancer. Pretty neat, eh?
What we’re building behind the scenes.
We ask for a VPC to be built (with the module I created in a previous post).
This gives us ‘private’ and ‘public’ subnets, and a NAT instance.
On top of that, we build out a mesos cluster
This comprises a number of pieces, first of all masters, which run zookeeper in addition to Marathon and Mesos. We run 3 of these by default, so one can fail without affecting the operation of the cluster. Also there are slaves which actually run the Mesos workers and excute applications. We launch 3 of these, and if one fails then any tasks it was running will be re-launched on the remaining slaves (assuming they have enough resources to do so!).
Then we deploy 2 load balancers which discover the running applications from the marathon API and configure nginx, with a publicly accessible ELB in front of them to provide HA, in the event one of the load balancer machines fails.
We push this into DNS, along with records for the adminlb machine. This machine is what proxies the mesos and marathon admin pages (and access to it is locked down to your admin_iprange.txt)
Redundancy and scaling
The cluster should be redundant to a load balancer or a mesos master failing. If the instance which fails can’t be brought back online, it should be possible to just terminate the instance and have terraform re-create it.
Also, you can eaisly adjust the number of slaves dynamically (just by changing the variable and running terraform), or the instance types employed (by rebuilding the cluster) if you’d like to run more tasks, serve real load from the cluster, or scale whilst already serving real load!
Marathon apps which have already been deployed can be scaled up (to more instances) just by using the Marathon API with a web browser – I encourage you to try this, scaling the example app up to 5 instances, or down to 1 instance and then killing 4/5 of the slaves.
TODOs
Currently the machine’s Internet access goes through a single NAT instance with no failover – we now deploy a NAT instance per AZ, so solutions are either:
- Have a route table per AZ to send traffic for each AZ out that AZ’s NAT box
- Have failover between NAT boxes (keepalived+modifying the route table(s))
The machines have no configuration management (no puppet/chef), which means that making any changes to them (or getting any security updates) involves rebuilding the instances.
Conclusion
Hopefully this post has shown that Terraform is already grown up enough to be used to compose real, production ready infrastructures.
The example shown here is not something I’d run as a production system, and there are a number of significant warts in the code (like having to pack and unpack lists into comma seperated strings), but there’s enough of the essential complexity represented here to be close to ‘real’ applications and deployment, and I’m still having a great time exploring Terraform’s rapidly growing capabilities, and producing reuseable modules.
Whilst I don’t think that anything but my most basic level of modules (e.g. AMI lookups) are likely to be reused verbatim, I hope this example shows that it’s possible to use terraform as a turnkey component in building repeatable and composable infrastructures.
Credits
Container Solutions have an excellent blog post on making a Mesos cluster on GCE – I stole it, converted it to AWS and added the service discovery/load balancing.